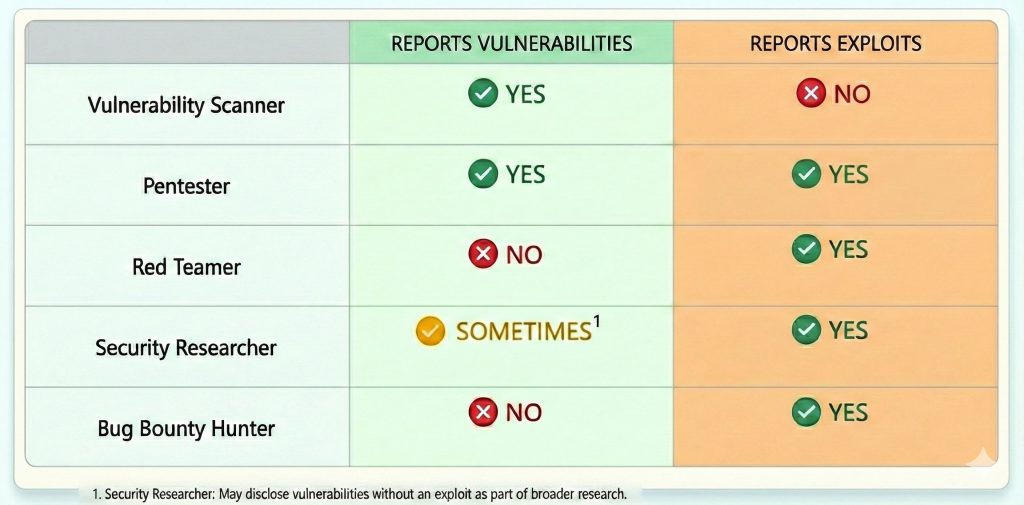
Bug Bounty and Vulnerability Disclosure Programs are growing at an alarming rate. At the end of 2020, I was monitoring over 800 companies across 3+ million domains on approximately half a million IPs. All of this data continues to be frequently updated as companies change their scope and assets. A pipeline provides passive income, while allowing for me to spend time working on other interesting projects and bugs.
Bug Bounty programs (BBPs) are companies that agree to pay researchers/testers for disclosed vulnerabilities. On the other hand Vulnerability Disclosure Programs (VDPs) publicly state that they will accept bugs through a communication channel, but do not provide compensation. VDPs will sometimes give out swag or place researchers on a hall-of-fame list. In the bug bounty community, there are strong feelings on which types of programs researchers should spend their time on. In general VDPs will have a less-hardened attack surface compared to BBPs due to the compensation. VDPs will generally be more secure than companies not accepting vulnerabilities from security researchers.
The first step in aggregating bug bounty data is determining what programs to hack on. From there, the program scopes need to be frequently retrieved in a reliable fashion. Researchers need to determine if they will test on BBPs or VDPs and if there are certain industries they want to opt out of, such as blockchain-contracts.
Where Do I Find Companies Accepting Vulnerabilities?
Various companies that are looking for vulnerabilities can be found on platforms like HackerOne, Bugcrowd, Intigriti, YesWeHack, and through sources such as disclose.io. Invite-only platforms exist as well, but have various requirements that may or may not play well with an automation pipeline.
An example of Spotify’s Bug Bounty scope can be seen with item’s such as *.spotify.com and *.spotifyforbrands.com.
Scraping Scopes
Bug bounty platforms provide a central repository for researchers to identify what companies are accepting vulnerabilities. They require companies fill out their profile page with rules and scope in a semi-consistent fashion. These profiles on a common platform allow for scraping. Some of them allow for unauthenticated APIs to be used, but there isn’t a great way to pull private program information without better APIs from the platforms.
One attempt is to use a tool such at https://github.com/sw33tLie/bbscope, which requires the cookies for each of your HackerOne, Bugcrowd, and Intigriti sessions and will then try to parse out the scope on each program.
I wrote my own solution a few years ago that grabs all programs on each platform and tries to parse out the scope from what each company wrote. My solution is very ugly and requires consistent refinement, but it works.
A lazy solution could be to just download a list of subdomains from public sources such as ProjectDiscovery’s Chaos project.
It’s important to pull this data on a recurring basis. This will allow you to obtain new companies that can be tested on. It will ensure that you have coverage for new domains that companies add to their platform profile and can be used to remove items from scope when they are no longer applicable to a company. As a side note, it’s a good idea to grab each company’s status. If they are not currently accepting vulnerabilities, then there is no reason to spend the compute time or energy gathering data.
Once you get the scope and any other bits of metadata you wish to store you can start to filter and perform recon on a company.
Recon
Automated recon has boomed over the last few years. There are new scripts and tools being added every month that are worth testing out to see if they fit into your bug bounty pipeline. It’s overwhelming to look at complex flow charts that have been built out by some researchers and determine where to get started. Test out some tools and find what works for you. Those tools and components can always be changed as your methodology matures.
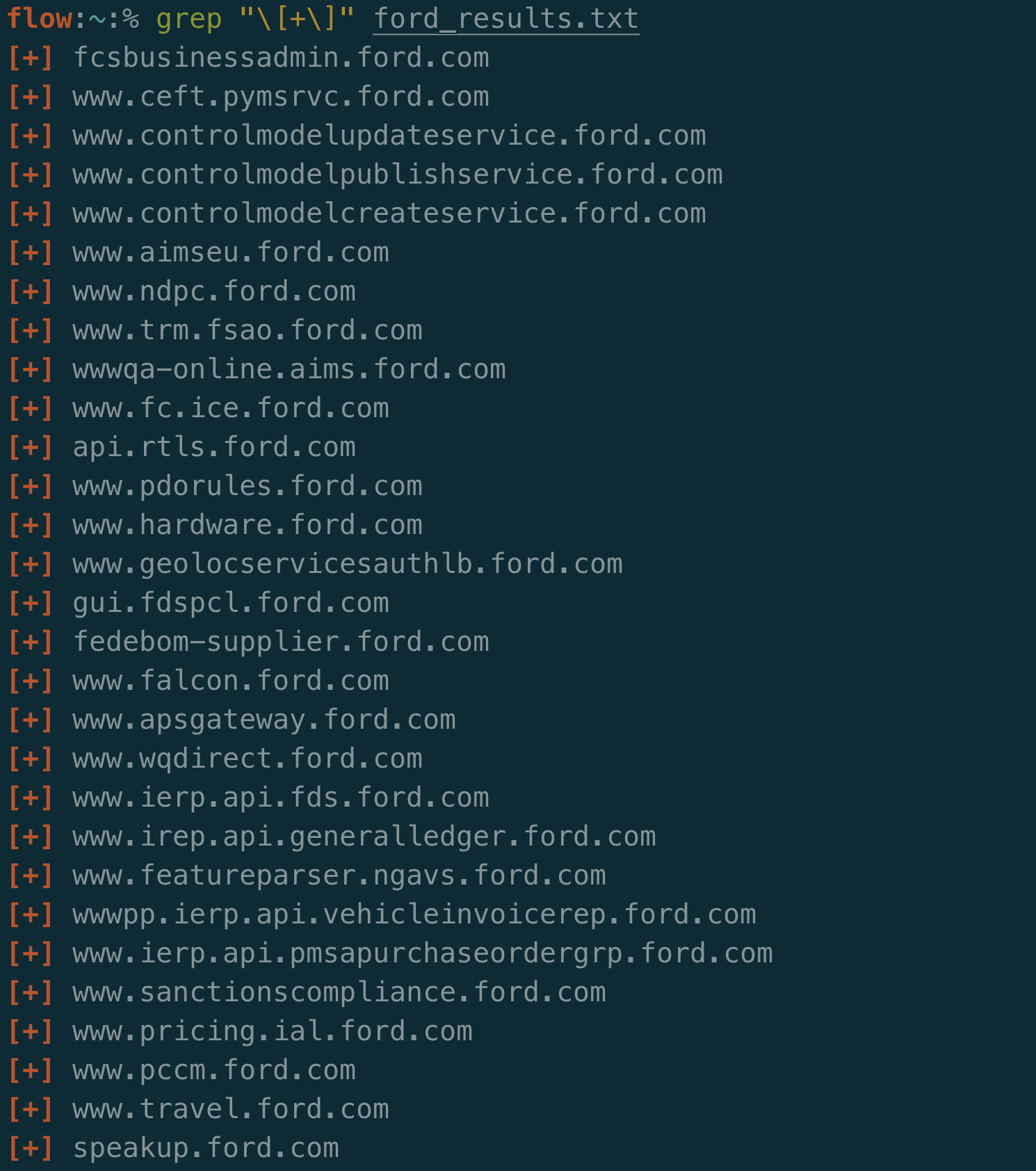
I start my reconnaissance by performing subdomain enumeration. This means I take companies with wildcard scopes and try to find all related subdomains.
I have found good results from using tools such as Amass, Subfinder, Sublist3r, and ProjectDiscovery’s Chaos. Many of these tools aggregate public and commercial APIs that pull out subdomains for a given domain.
Some researchers will perform DNS bruteforcing to identify additional subdomains using a list like Jason Haddix’s list in SecLists. I personally don’t perform DNS bruteforcing, but it’s a good candidate for improving a pipeline.
After identifying a large list of subdomains to test, that data should be filtered to only what is relevant. Any filtering that can be done upfront will save hours of time in the future. Running large lists of domains through scanners and tooling will greatly slow down and break pipelines. A good start is to check what is online. This status may be defined by DNS resolution or by the availability of some network service such as HTTP.
It’s worth determining if the metadata, IP and relevant ports, are valuable to keep in your inventory or if your pipeline should retrieve fresh data consistently. My preference is to store that data and periodically check stale records to see if they are still accurate. It’s excellent to be able to automatically query network data and associations when writing test cases.
If maintaining an inventory of IPs and ports is of interest, then DNS resolutions and network scans are a large portion of ongoing recon. Massdns is a frequent suggestion for checking to see if many domains are online. It requires a list of DNS resolvers to be updated regularly. Nmap is the most famous network scanner, however masscan, naabu, and rustscan offer faster results with reduced coverage/detection. It also depends what is of interest. There are 65535 TCP ports that can be scanned, which can take a significant amount of time. It may be valuable to scan some UDP ports as well. Network scanning can provide valuable information such as what type of software is running on a given port and can even be configured to run vulnerability scans against that service.
The gathered IPs can be analyzed with services such as Shodan to perform passive network scanning on your behalf. Additional metadata can be grabbed from these services such as the ISP and if it’s hosted on the cloud. The downside is that the rate limit for many of these services is slow and checking hundreds of thousands of IPs at a time can be a bottleneck.
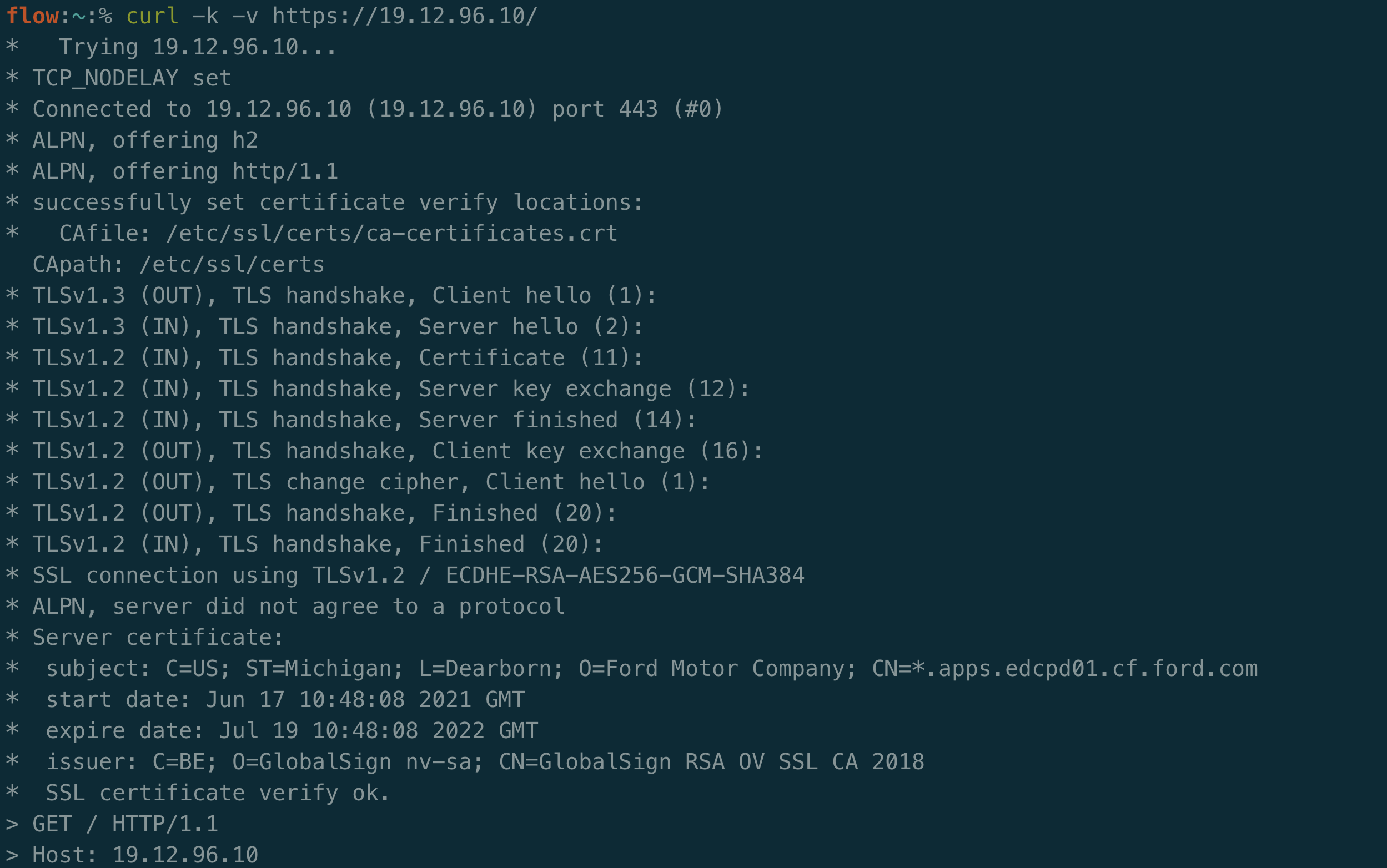
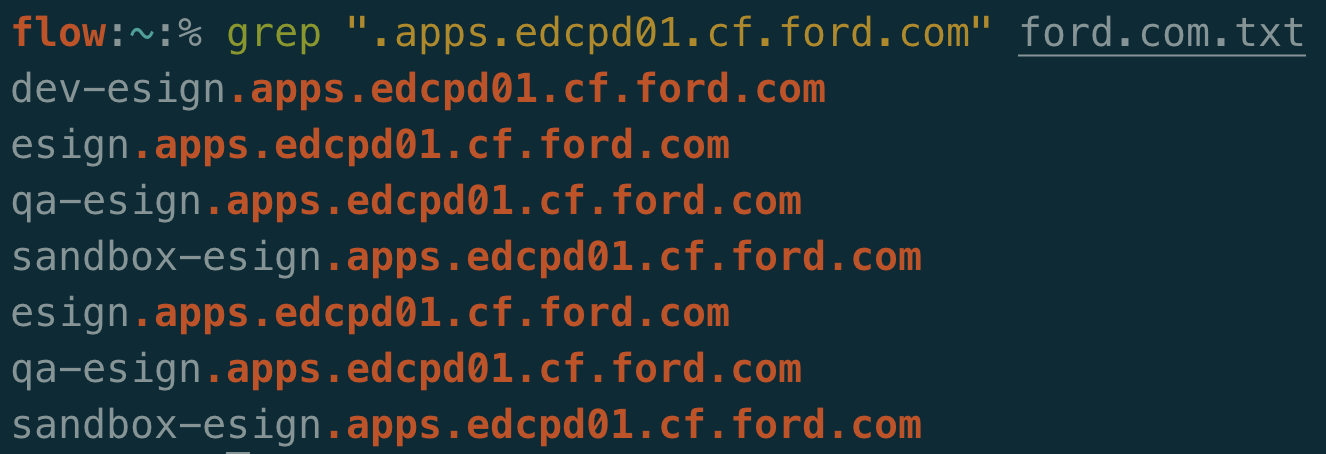
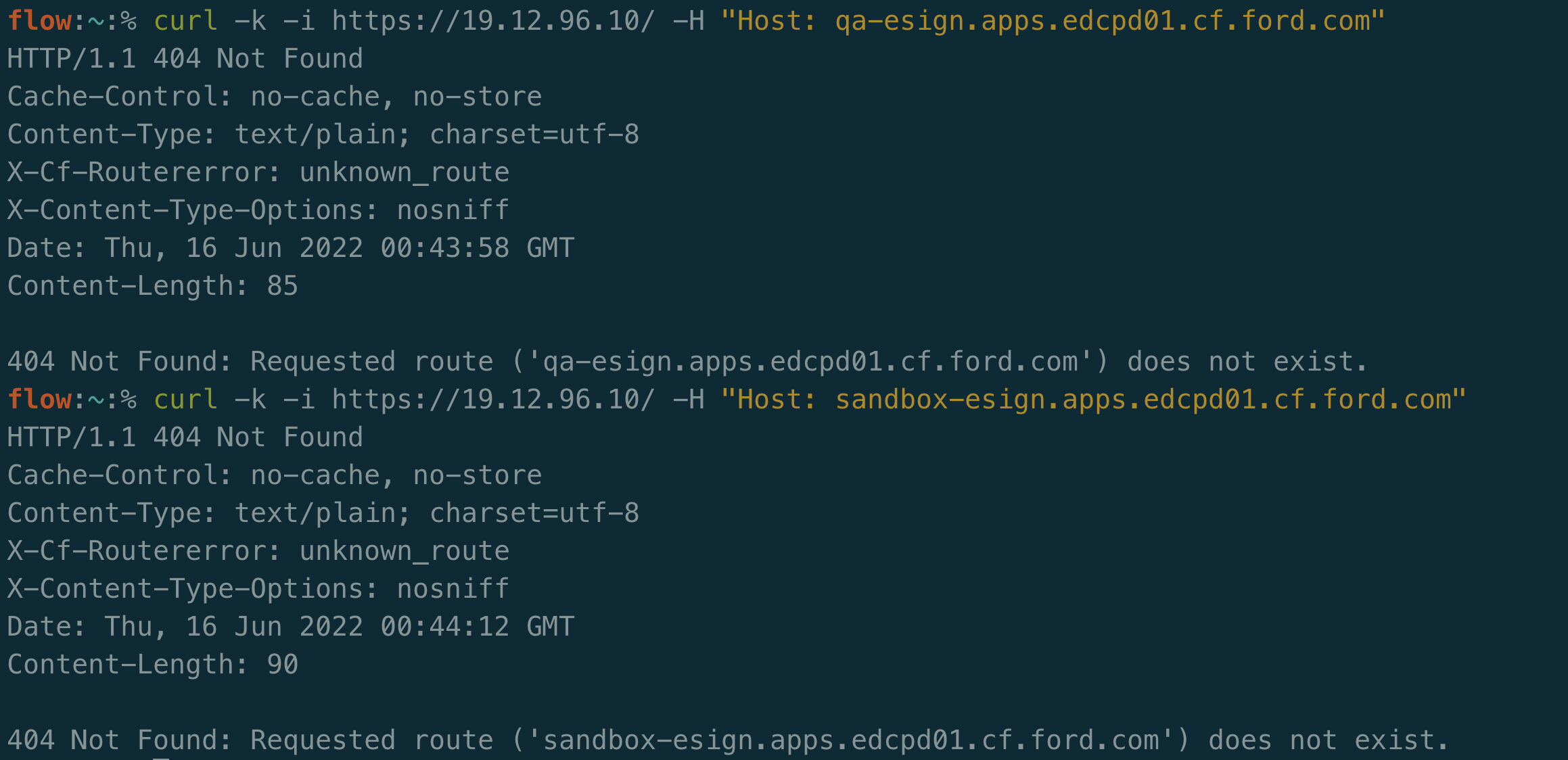
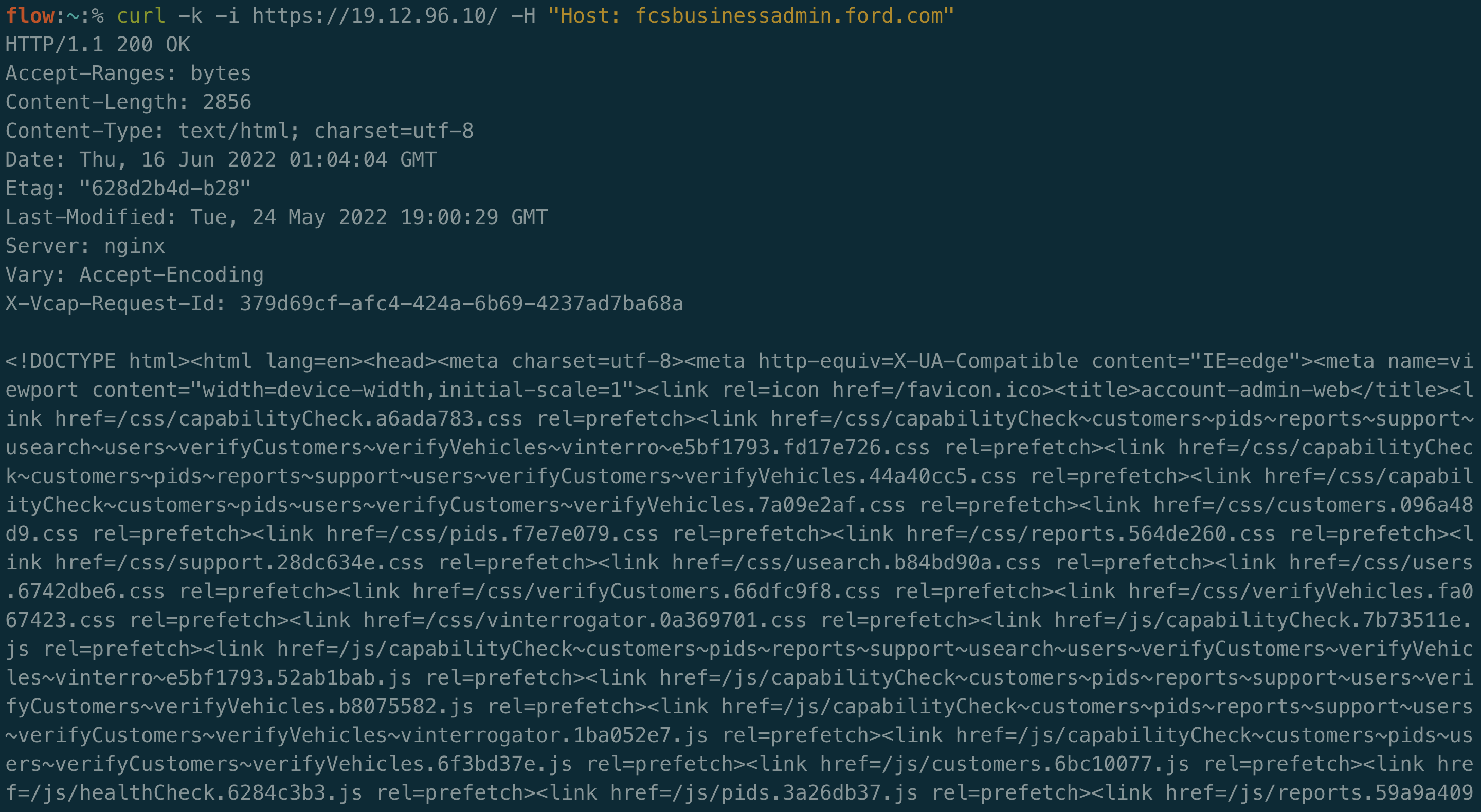
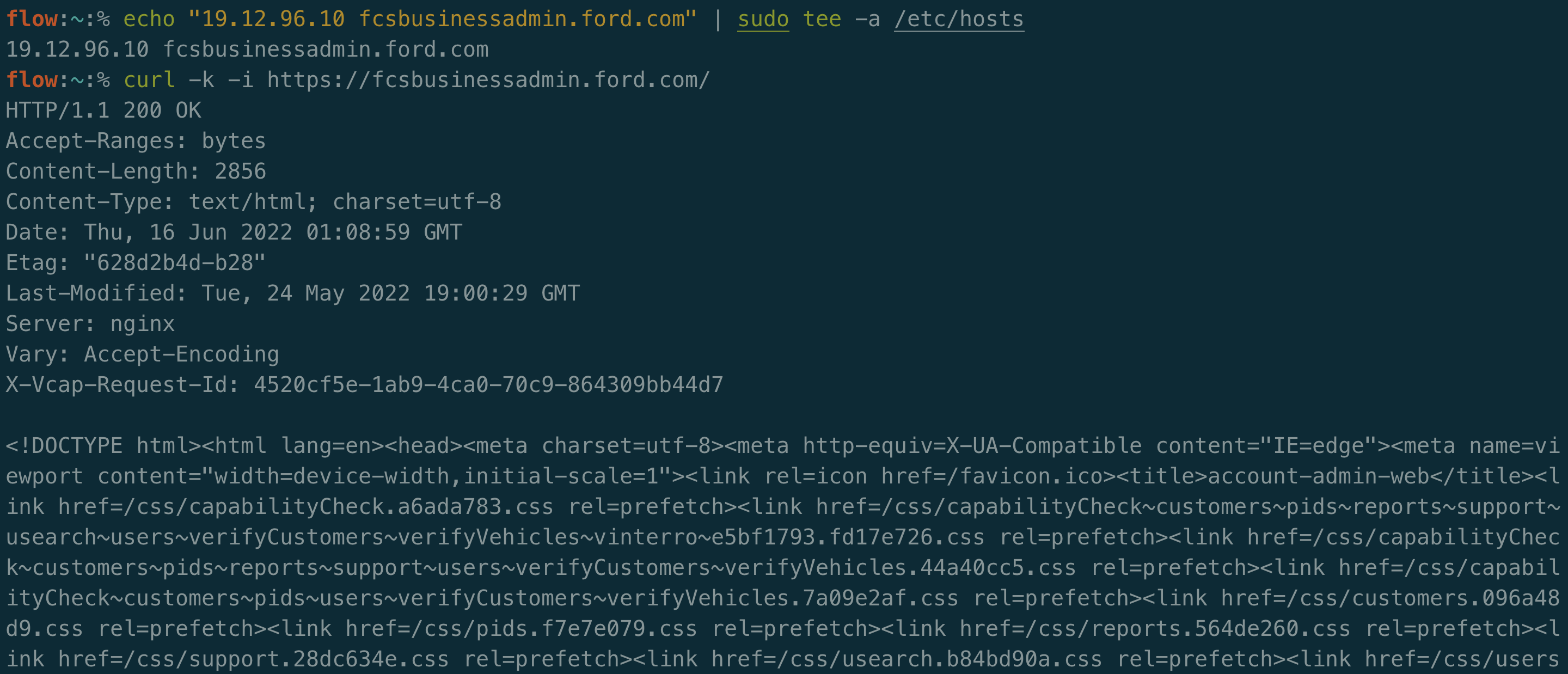
You may decide to filter out subdomains and domains that are offline. This will certainly save space and time as you recheck this data, however it can be useful to keep around. Unresolved subdomains can be used for virtual hosts fuzzing and easy proof of concepts for Server-Side Request Forgery (SSRF) vulnerabilities that allow you to request a company’s internal content.
At minimum, common web services should be identified and tested in a bug bounty pipeline. Port 80 is commonly used for insecure traffic (http), while port 443 is used for TLS traffic (https). An extended number of ports such as 3000, 3001, 3002, 8000, 8080, and 8443 may be commonly seen as well. I highly recommend using httprobe to identify what domains are online and if they are accessible through https, http, or both.
Some other items that may be interesting or relevant to grab:
- Screenshots
- Wappalyzer Tags
- DNS CNAMES
Storing and Managing the Data
The scope from the platforms and the reconnaissance data can become quite large after some time. In an automated system, the data needs to be stored and processed automatically. It needs to be frequently queried and updated. The ideal scenario would be to use an API to manage this entirely or certain components.
There are a few main tables that need to store the appropriate data. I have a Company, Site, IP, and Vulnerability table in my database. I created a join table to map IPs to sites and vise-versa, which allows me to be very efficient in translating this data. Some companies list out their public IP range as part of their scope, so another possibility would be to link IPs to companies. At the core of it, a simple database is required with a lot of data.
Any framework or language could be used to create this central database. The bulk of the effort is in the endpoints that process the data and requests. Some questions to ask are:
- How do I want to interact with a company’s data?
- Do I need aggregate or individual results?
- How do I handle large HTTP responses?
- How much metadata do I intend to store on each table?
A secondary consideration is how to trigger events and queue jobs. Cron works great to schedule time-based tasks. An example would be to fetch the scopes of all bug bounty companies at 5 PM daily and send any new data to your reconnaissance suite. Certain jobs such as importing hundreds of thousands of records from sites like Yahoo may take up all of your APIs CPU. You may want to consider storing those and processing them in batches.
Some bug bounty hunters will store this data in folders on a filesystem and stitch everything together with bash scripts. I prefer using an API as it provides more granularity on how I want to shape the data, it allows me to stay organized and consistent across companies, and it can easily be deployed to different systems.
The Fun Stuff – Finding Vulnerabilities
At this point in the journey there are some systems set up to continuously grab data and start working on it. That data is stored and can now be queried based on how many attributes you have stored. This leads to a lot of exciting potentials.
As part of a MVS (minimum viable scanner) the bug bounty pipeline needs to be able to pull a subset of the data it has collected and start to scan or fuzz it for vulnerabilities and then report back positive results. It would be possible to auto-report these issues to companies, however I discourage doing this as scanners can have false positives. Results should always be manually reviewed/exploited.
A strong baseline would be to implement functionality to run ProjectDiscovery’s Nuclei scanner on all of your domains on a rolling basis. This means that once it runs through your list, it starts over again. The scanner and templates are continuously updated by the community, which takes the work out of writing test cases for CVEs and common misconfigurations.
If you have read my Metasploit’s RPC API article, then another option could be to attempt to automate the community version of Metasploit against your targets. Metasploit provides the check command on a large number of modules that have a default port associated with them. Metasploit is regularly updated by Rapid7 and is another great way of attempting to automate without recreating the vulnerability signatures manually. A successful vulnerability will likely give you a shell, which will likely be a critical severity vulnerability.
Some other options would be to write your own modules on a regular basis or run other people’s scripts that can be incorporated into the pipeline. They can be efficiently tested by querying applicable network services or web application technologies instead of scanning all assets for a specific vulnerability.
Once a scanner has identified an issue it needs to report back to the central database. It’s great to aggregate the data in one place, but with fast-paced 0-days you need to know within seconds of identifying the vulnerability if you want to be first to report a bug. A notification system is a good idea to have in your pipeline that can be configured to get your attention depending on a variety of factors such as severity and confidence. Slack and Telegram provide free methods of sending notifications. AWS and Twilio can be used to send SMS messages. There are a lot of free and paid products that can be used to send events for a variety of events in your pipeline.
Building the Infrastructure
A large part of bug bounty hunting is to bootstrap a bunch of technologies together to achieve automation. Scripts have to be modular enough for you to be able to swap out tools and components. Some pieces in the pipeline are essential and are unlikely to be disrupted, however the code that glues it all together should allow for an easy upgrade.
Most of what I discussed in this article can be ran for $5-10 in the cloud each month, which is $60-120 a year. That is cheaper than most security tools and it can be used to fund itself through earned bounties.
I’m a huge fan of Axiom, which allows you to create a bug hunting image on DigitalOcean, AWS, etc and spin up a new instance via command line in a matter of seconds. The base instances that cloud providers release are generally sufficient for any type of scanning and are fairly cheap. Axiom wraps the infrastructure code into a bundle of command line tools that allow for IP rotation, distributed scanning, and most importantly pay-for-what-you-use tooling. Customizing the base Axiom images is fairly easy and provides a great starting point.
Automated tooling like this allows for a researcher to spin up an instance or several for a few hours to run through a test suite and then delete all of the instances to prevent additional costs. It ensures that they servers are using the latest copy and that there isn’t any remnant data that might cause problems.
I like use a queue to track the state of my scanners. As I said at the beginning of this article, I have a few million domains that I’m tracking. On a single instance, I likely can get through a few thousand scans in a couple of hours. Using software such as Redis, I can load all of my data into a job-specific queue and parse it with any programming language. I can pop the appropriate jobs from the queue for a given time-frame and then execute my tests. When the queue is empty, I can move on to the next test or decide to replenish the queue with fresh data from my database.
When deciding on an infrastructure, spend the time to play around with the technology until you feel comfortable bootstrapping with it. Ensure that there is enough community support to incorporate software into your stack because you will run into problems.
A Million Forks in the Road
Bug Bounty pipelines are necessary to bug hunters that are looking to test against a breadth of companies. They can range from simple bash scripts to entire networks of bots and micro-services. Pipelines allow for regression and excellent methods of staying organized. They can easily surpass what any person can manually accomplish, yet they will struggle on certain types of bug classes that can’t be easily automated. In it’s first year, my pipeline has managed to pay for itself for the next 20+ years.
There are a handful of improvements that can be made to cover various technical domains and techniques in my pipeline. Each person gets to choose how they want to build their pipeline and what they want it to focus on. It’s easy to extend tables and increase data sources. Automatically ingesting new CVEs and vulnerabilities from the community is powerful and requires minimal effort. When you have started building or planning your pipeline, I encourage you to ensure that the code you write is modular, reinvent the wheel as little as possible, and iterate consistently.
Hit me up on Twitter @wdahlenb with stories about your Bug Bounty pipeline.